|
Ng Chu Ming (黄祖铭) B.Eng in Computer Engineering (2nd Upper), National University of Singapore - Maj. Gen. William C. Lee (101st Airborne)
|

|
|
Chu-Ming is a Singaporean chinese and is currently Core Strategist, Vice President with the CIB Core Strategies Group in JPMorgan Chase & Co. Inc. The Core Strategies Group is a quant developer group working in foreign exchange, commodities, emerging markets, and mortgages. The group covers the market making businesses, mainly on the derivatives side, though also in foreign exchange electronic market making and hedging algorithms. We build the trading and risk management platform Athena (see also Risk magazine on Athena ). Prior to JPMorgan he was Associate Director with UBS Investment Bank where he was development lead for it's inhouse electronic trading and smart order routing system for equities trading based on UBS Pinpoint technology. Before joining UBS he was Analytics / Pricing developer in Electronic Trading Technology with investment bank Merrill Lynch & Co. Inc. His work in Merrill spans the design and architecture of timeseries/bitemporal databases and also quantitative analytics using the vector processing language Q. Notable work done in Merrill include the proof of concept implementation of integrating Q with Nvidia's CUDA API, bringing 6-8x performance gains in analytics such as full day VWAP computation. He also worked on the design of multithreaded Java Analytics API for algo trading engines. In this area he introduced Google's MapReduce inspired distributed processing, improving full day VWAP for the entire US equities universe by 5x. Before joining Merrill, he has experience in large scale software development during his tenure as Software Development Engineer with Autodesk Inc working on the Vault-Addin, which is part of the flagship AutoCAD drafting software.
He received his Bachelor's degree in Computer Engineering (2nd
Chu-Ming's broad interests include Computer Graphics and Visualization, Computational Geometry, as well as data structures and theoretical aspects of computer science. He is also interested in algorithmic problem solving. Specific areas of interests and expertise include out-of-core terrain visualization, surface reconstruction, geometric algorithms, spatial data structures as well as automatic design generation of building forms. He is also experienced in large scale C++ software development, design patterns, OOAD from his experience working with the 25 years, 9 million lines code base of AutoCAD. His other interests outside of academia includes wushu, inline skating, bike tricks. He is also into long distance running and successfully completed a full distance marathon in the Standard Chartered Singapore Marathon 2006 In his past life, he also served as a paratrooper with the 1st Commando Battalion, Singapore Armed Forces. Quick Links
Jeff Erickson's 3D Pancakes His theory page here Erik Demaine This guy is a G.E.N.U.I.S. The youngest professor ever to be on the faculty of MIT at age 20 Herbert Edelsbrunner Grand supervisor (supervisor's supervisor) The only computer scientist to win the Alan Waterman award. I sure wish I can meet him one day! Publications
Talks
Research InterestsComputational geometry, computer graphics, terrain visualization, architecture form generation. I love computational geometry and in my free time I enjoy thinking about shapes and their application to graphics. My greatest fascination is with Dual space algorithms such as the Dual Space algorithm for solving the Stabbing line segment problem, as well as the lifting transformation for computing 2D Delaunay Triangulation via lifting it up to 3 dimensions. Taking things up one additional dimension sometimes provide a new dimension of insights, such as that for Moebius Transformations.
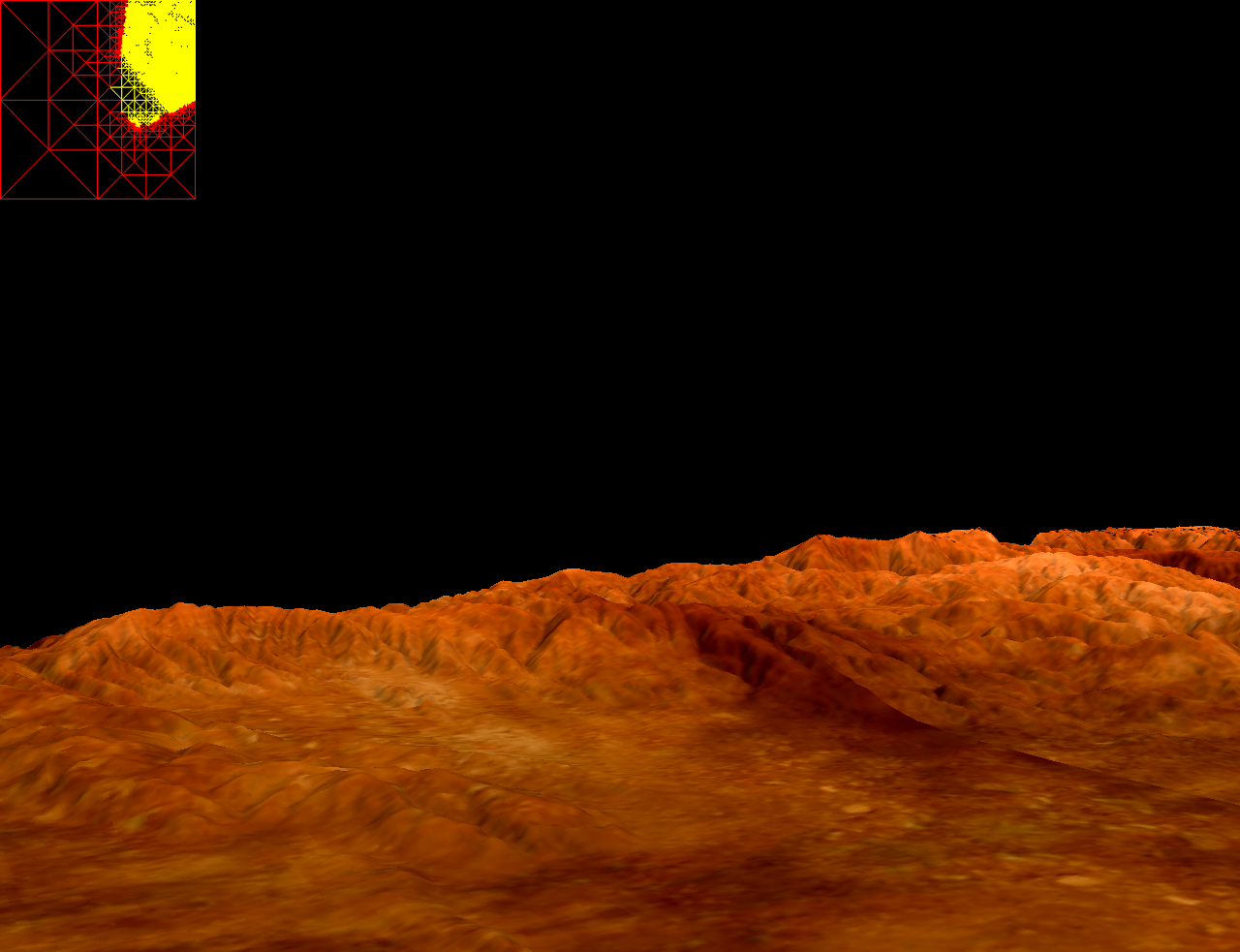
Terrain Visualization (dyanamic level of detail for terrain walkthrough, based on ROAM)
Screenshots of the level of detail terrain engine with multitexturing of terrain textures.
Illustration of dynamic tessellation of terrain geometry as the view point changes. Notice that the regions in-view (shown in yellow) are more highly tesselated. Similarly, flat regions are less tesellated to save triangle budget. The rectangular grid in the top left of each image shows a top down view of the terrain geometry from frame to frame.
|
|